Today’s blog post was contributed by Bruno Sousa, spacecraft operations manager for the Cluster mission at ESA’s ESOC mission control centre, Darmstadt, Germany. Cluster was launched in 2000 and comprises four identical spacecraft (Rumba, Salsa, Samba and Tango) orbiting in tight coordination with each other, collecting the most detailed data yet on small-scale changes in near-Earth space, and on the interaction between the charged particles of the solar wind and Earth’s magnetosphere.

We can monitor in real time the progress of operations from anywhere! Credit: ESA/B. Sousa
I happened to be on call one weekend a few weeks ago, and I knew there were several contacts between our spacecraft and our ground tracking stations scheduled that were going to be unattended.
Since the beginning of 2015, we have been working towards a reduction of the continuous, real-time human presence in the Cluster control room. We initially introduced short periods when no Spacecraft Controller [‘Spacon’ – Ed.] is in the control room and, more recently, in 2016, the duration of the periods without a Spacon physically present to look after the fleet has been increased, which required a greater effort by the team to be even more flexible with shift planning.
As a result, we rely heavily on our automated system both to assist controllers when they are present in the control room, and also to run some of the spacecraft ground-station contact passes fully autonomously, that is, without any human intervention. The system does this very well, as long as everything in our ‘system of systems’ that comprise what we call the Cluster ground segment is working fine.
But on that day, this wasn’t the case.
The Ariane 5 V188 launcher carrying Herschel and Planck rises above ESA’s 15 m-diameter tracking dish at Kourou, French Guiana, on 14 May 2009. Credit: ESA/A. Chance
A problem at ESA’s Kourou station caused all of their pre-planned automated tasks to be shifted by a full five minutes. This meant that our planned pass activities and theirs were no longer perfectly synchronized, as usual (Editor’s note: Scroll to the end to read a brief description of what’s involved in a ground station pass).
As a result of this glitch, our system started conducting the pass as scheduled, but as it attempted to change the data rate on the spacecraft, it lost contact because the station was late in doing the same, and after timing-out, it gave up and aborted the pass.
This being a Sunday, I was at home playing with my kids, initially oblivious of what was actually happening at ESOC.
I did, however, have my tablet with me, so a few minutes into the pass, which I knew was going to take place, I snuck into the kitchen for some peace and logged in to check progress. I had done the same already some three hours before to check the previous pass over ESA’s Maspalomas station, which had worked just fine. Now we were about to track, once more, Tango and Samba simultaneously with the same Kourou antenna.
A quick glance at the Cluster fleet management portal, which we call Clusterweb, immediately told me something was not right. Several minutes into the pass, the on-board ‘used storage space’ on Tango had not yet started to decrease; this meant we were not downloading our science data.
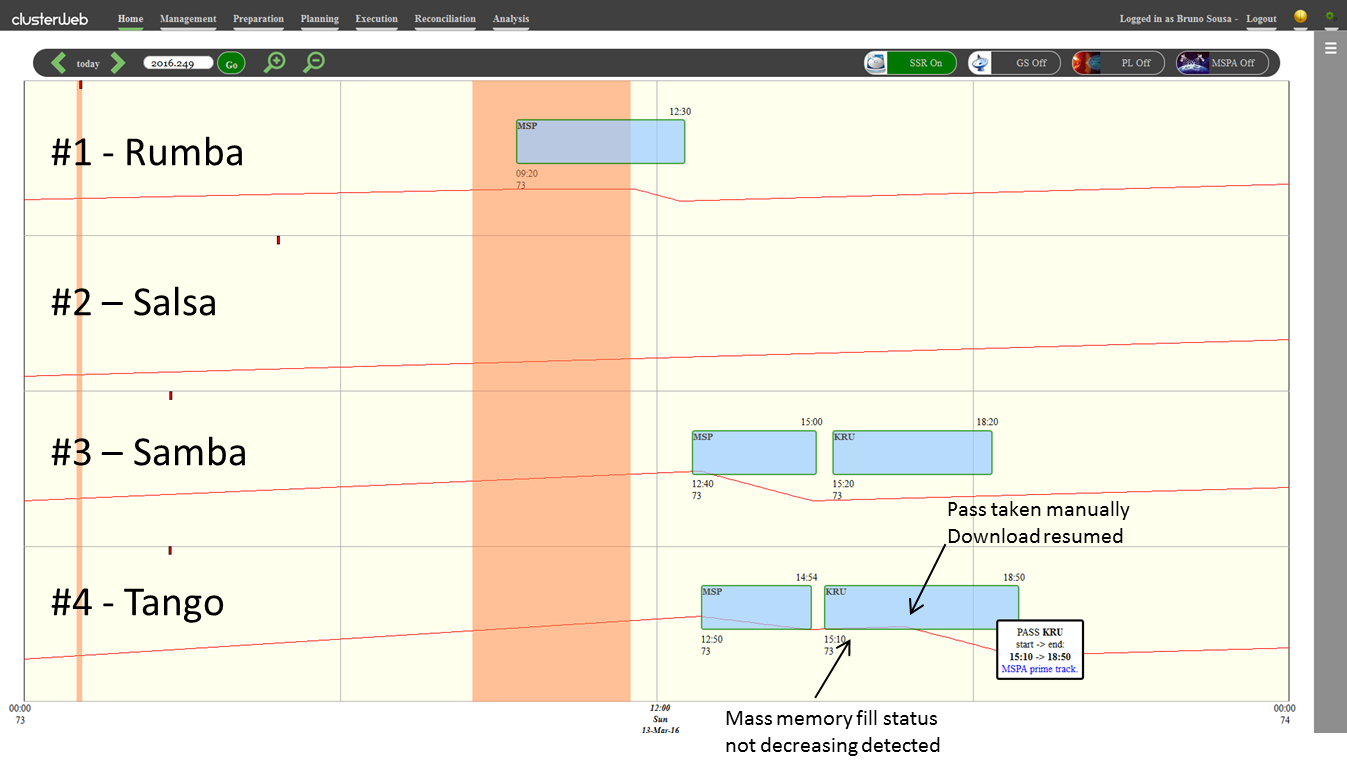
Clusterweb: The red line shows how much on-board storage is filled for each spacecraft. Shortly after the start of a contact, it should decrease as the science data are downloaded. Credit: ESA
Now concerned, and looking for more detail, I immediately checked our digital logbook, which is like a ‘Facebook for Operations’, where our Automation System and our Spacons regularly post everything they are doing and checking. Sure enough – I saw that after an initial successful Acquisition of Signal (AOS), the system had failed to confirm the change of Telemetry Acquisition Mode (TDA) – the setting of a higher bit rate for science downlink mentioned earlier – and had therefore decided (autonomously) to abort the remaining pass operations.
At this point, I knew enough to determine that I would need to intervene manually. After waiting a few minutes for my wife to return home and stay with the kids, I hopped in the car and came into ESOC (a 10-min trip on a quiet Sunday afternoon), walking briskly into the Cluster Dedicated Control Room. Sitting at the Tango spacecraft workstation, I re-established the science data downlink manually, adjusting for the out-of-sequence timing, and the pass could thereafter continue as planned. For now, the problem was solved!
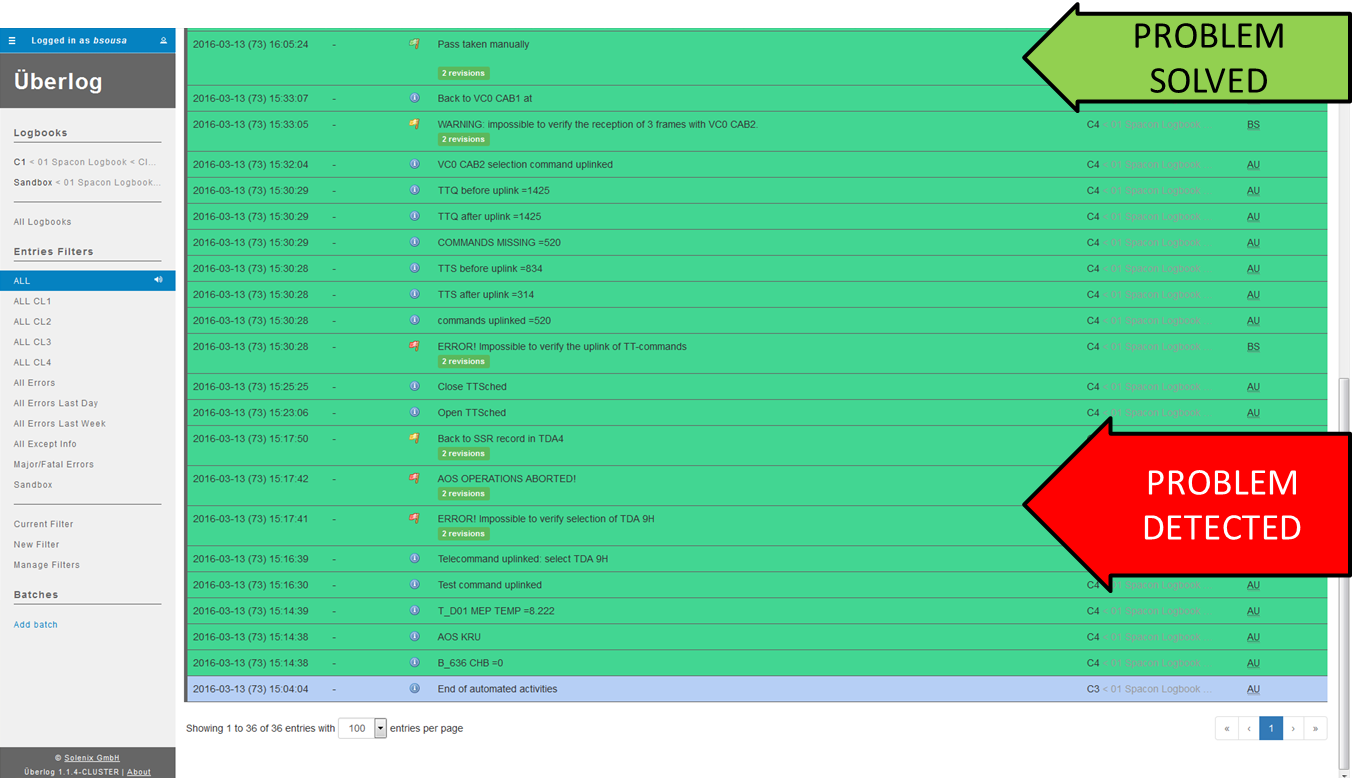
Cluster digital logbook: This digital logbook works like the Facebook timeline; our Automation System and human operators post constantly what is happening during the contact, the newest posts are on top. Messages are categorised according to criticality. Credit: ESA
The actual cause of the issue at Kourou station was only discovered some days later, after further investigation. It’s the sort of thing that happens only very rarely, so there was a bit of bad luck involved (and – for some mysterious reason – this type of rare event always happens on a weekend or at nights…).
But the point of this story, and what it demonstrates, is that it is possible to fully automate the monitoring and control of the spacecraft, and that you don’t need to try to cater for every possible thing that could go wrong. What you do need to ensure is that the system knows when it’s safe to proceed and that you have in place sufficient tools to give the on-call engineers clear situational awareness of what is happening in the control room. Clusterweb does just this for us.
Clusterweb is a prototype developed by the Cluster Flight Control Team and has become an essential part of our operations concept.
We have actually just kicked off a new project to re-engineer the software from scratch, developing it into a more mature and clean product that could also be deployed for other missions. Besides supporting us with fleet monitoring in real time, the tool is also incredibly handy in supporting us in the pre-operations phase, with planning, and in post-operations with reconciliation of the completed operations.
The other tool we’re using is called Überlog; it is an off-the-shelf product we have licensed from Solenix GmbH, which allows humans and our automation system alike to log instantaneously what they are doing while operating the fleet. It also enables engineers to be notified by email of any noteworthy events.
Colleagues from several other missions here at ESOC have indicated they would like to adopt this system, so site-wide licensing and deployment is currently in the pipeline. Both tools are based on well-known web technologies and are therefore accessible anywhere with a browser.
In summary, ground automation coupled with a good, high-level, remote situational awareness setup allows both for operations to be run without local human support (‘lights out’) and, alternatively, the same level of human resources can monitor a greater number of spacecraft at the same time.
In any case, the role of the human being in real-time spacecraft operations is changing, from being an integral component of the control loop to becoming its supervisor, which is typically the case when the knowledge and experience of systems reach a certain maturity and the tasks become repetitive and predictable and can therefore be easily automated.
Editor’s Note: It’s helpful to know what is involved in a ground station pass for one of the Cluster spacecraft. Typically, following a very detailed and tightly planned schedule, the station will begin setting itself up for the pass. It will rotate and elevate its antenna to point at the spacecraft’s expected location in the sky, it will configure its software to synchronise the radio frequency, the bit rates and other parameters needed to establish the link, and then, a few minutes before the expected ‘AOS’ (acquisition of signal), it will sit quietly, waiting, marking the ‘beginning of track’ time.
Shortly, the spacecraft will appear, rising above the horizon; it will already be transmitting (the command sequence to trigger this will have already been uploaded in a previous pass) and the station will begin receiving the signal; the two are now in contact. During the pass, which can last several minutes up to several hours for Cluster, the spacecraft and station will conduct a series of downloads of spacecraft status and housekeeping info (‘telemetry’) and scientific data recorded by the instruments, and uploads of new instructions (‘telecommands’).
When all is complete, the two will stop communicating, drop the link and the pass will formally end. This typically happens when the spacecraft orbits out of station view, below the horizon. The station is then freed up to go to its next assigned pass.
Discussion: no comments